Introduction
What Are Duplicates?
Have you ever looked at a list of numbers and thought, “Wait, didn’t I just see 42 a moment ago?” — that instinct is exactly the problem we are solving today, which is finding Duplicates in an Array.
In simple terms, finding duplicates in an array means scanning a collection of items and identifying which ones appear more than once. Imagine a basket of fruit: you want to know which types you have doubles of. That is precisely the challenge.
This is not just a textbook exercise. Duplicate detection is a fundamental skill in data cleaning, security, and system design — and it is a favourite topic in technical interviews.
Real-World Scenarios
E-Commerce
Preventing a customer from applying the same discount code twice to their cart.
Data Science
Cleaning “dirty” data where the same user record was entered into a system multiple times.
Security
Detecting “Double Spend” attacks in digital transactions and blockchain systems.
Problem Statement
We are given an array of integers with a carefully defined set of rules that make an efficient solution possible:
- The size of the array is n.
- Every number in the array is between 1 and n (inclusive). An array of size 5 contains only values like 1, 2, 3, 4, or 5.
- Each number can appear at most twice, so no value repeats more than once.
Input & Output Format
Input: A single array of integers satisfying the above constraints.
Output: A new list containing only the numbers that appear more than once. If no number repeats, return an empty list.
Examples
Inputarr = [3, 1, 2]
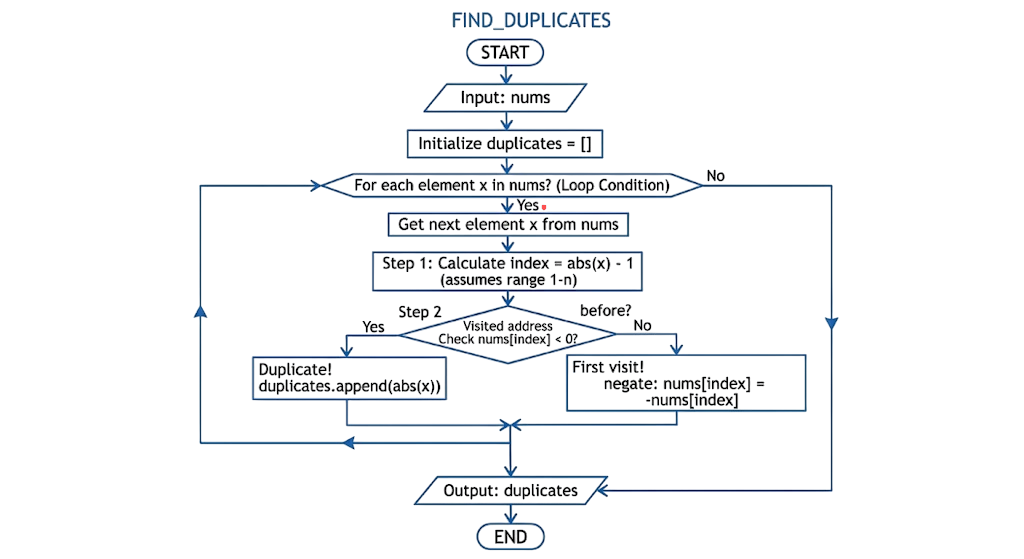
Pseudocode
duplicates ← empty listFOR each element x in arr:
idx ← abs(x) − 1IF arr[idx] < 0:
append abs(x) to duplicates
ELSE:
arr[idx] ← −arr[idx]RETURN duplicates
Python Program
def find_duplicates(nums):
duplicates = []
for x in nums:
index = abs(x) - 1
if nums[index] < 0:
# Already visited → this is a duplicate
duplicates.append(abs(x))
else:
# First visit → negate as a "visited" marker
nums[index] = -nums[index]
return duplicates
n = int(input())
my_array = list(map(int, input().split()))
print(f"Duplicates found: {find_duplicates(my_array)}")Explanation
STEP-1: The Mapping Strategy
index = abs(x) - 1Computers start counting at 0, but our data starts at 1. Subtracting 1 bridges this gap — value 4 maps to index 3. We wrap in abs() because previous iterations may have negated the stored value; we need the original to find the correct address.
STEP-2: The “Checklist” Logic
if nums[index] < 0:
duplicates.append(abs(x))Before acting, we check the value at the target index. If it is already negative, another element has previously visited this “address.” Two elements pointing to the same spot means the current value is a duplicate — we record it.
STEP-3: Leaving a “Visited” Mark
else:
nums[index] = -nums[index]If the index holds a positive value, this is our first visit. We multiply by −1 to flip it negative — this is the “I’ve been here!” flag. No extra memory is allocated; we reuse the array itself.
Complexity
Test Cases
| Case Type | n | Input Array | Expected | Reasoning |
|---|---|---|---|---|
| Standard | 5 |
2 3 1 2 3 |
[2, 3] |
Verifies the code finds multiple duplicates correctly. |
| No Duplicates | 3 |
3 1 2 |
[] |
Ensures an empty list is returned when all values are unique. |
| All Pairs | 4 |
1 1 2 2 |
[1, 2] |
Checks behaviour when every element in the array is a pair. |
| Single Duplicate | 4 |
1 2 3 1 |
[1] |
Confirms it works when only one number is repeated. |
| Large Value | 2 |
2 2 |
[2] |
Tests the boundary where the value equals n itself. |